

photo by DEZALB
For the first time I am on the project that has big enough Data Warehouse tables that could be partitioned. While many data warehouses are big, in my previous projects a single table has rarely exceeded a few million rows, which means it is too early to think about partitioning. Other obstacles on my way to partitions was the limitation of this feature to the Enterprise Edition of SQL Server in earlier versions and no visual interface. Good news is that partitions are now available to all SQL Server users on all editions, so anyone could try it without finding a way to access the exclusive Enterprise world.
Where to start?
To enter the magnificent world of table partitioning I would recommend reading this Cathrine Wilhelmsen article. The best part of it is pictures, which makes it much easier to understand the technical side of it. However, table partitioning starts with determining the need and careful planning before the implementation. Not every big table should be partitioned and not every partitioning solution is the best.
It would benefit the most if users could get all the data they need from one partition without needing to scan two or more table partitions. Therefore, partitioning should be meaningful to the business. Alongside you could find the partitioning column by asking questions to the business users. E.g. data is selected by periods, then the date column is one of the good candidates for being a partition column. The scenario with the time-based partition is also good for archival perspective: partitions with the old data could be compressed and put into cheaper disks if rarely used. If the business can’t see such portions of the data, then probably partitioning won’t resolve the problem with the big table.
SQL Server supports partitioning by many columns types. If your situation is complex and require partitioning by multiple columns you’ll have to create a computed column to concatenate them into one value.
Once you have figured out the partitioning column and function, you can test it before applying to the actual data by using $PARTITION function. It provisions a partition for a data row based on partition function and partition column value. Once partitioning is applied, partitions details could be queried with the system views, sys.partitions, sys.partition_functions, sys.partition_range_values and many more; you can find plenty of helpful queries combining them into nice output in the internet. If you did everything right, all the partitions of the same table will have about the same number of records. If one of the partitions contain 90% of table records and some of partitions are empty, you should reconsider partitioning strategy.
File groups
Microsoft really wants us to store partitions on the different database files; the whole idea of partition scheme is to map partitions to filegroups. Their biggest reason for that is partitions independence during the disaster recovery, i.e. the most recent partition could be recovered first and brought online for users, while old partitions are still in process of restoration.
However, there are quite a lot of people in the internet who say that it doesn’t work for them. In case if database files are located on different disks, SQL Server will have to scan through them one by one in order to bring you the data from different partitions. Which is not a concern if you have your hardware tuned up.
Ask Harry
There is no visual interface to show in SQL Sever Management Studio whether a table is partitioned or not and what are the partitions. But SQL Server, like Hogwarts, full of wizards! There is one to help you in partitions creation, one to help you in managing them and one to manage compression by partition. You can find them all under the Storage menu when you right-click on a table.
Create Partition Wizard require database filegroups to be in place before you start, but it will help with partition function and scheme creation. I really like the screen where you define boundaries for partitions, SQL Server can estimate a row count and space it will take (most likely it’s the same $PARTITIONS function running underneath):
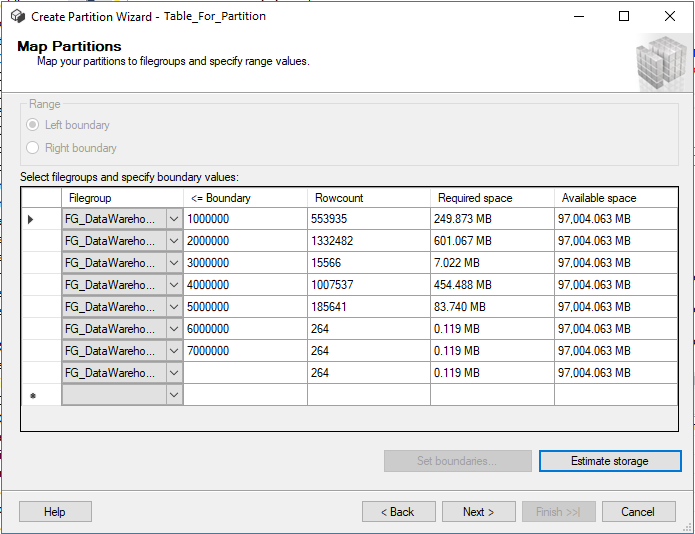
It’s easy to evaluate the quality of partition function before applying it; rowcount distribution doesn’t seem even
Use Manage Partition Wizard for switching data out and into partitions; which means emptying a partition into a separate table and pulling data back into an empty partition of the table.
If you are sure that a partition contains only the old data which will never be used, but should be kept there just in case, Compression Management Wizard will help with a partition compression. Selecting the data from compressed partitions cost more CPU, but it helps to save storage space.
Conclusion
‘When it gets big, we’ll partition it’. Table partitioning may look like a magic solution for tuning up any big table. However, magic won’t happen if partitioning is not implemented correctly and not used properly. A decision about partitioning strategy should be made collectively by business users, ETL developers and database administrators. Otherwise it could make things worse rather than improving the situation.
Kate
Data masseuse
