Pre-ramble
So there I was on a client site, and we had some standard structured word documents that needed to be read in via a Power Automate Cloud flow. Microsoft Excel spreadsheets - not a problem - nice handy connector and a table read action that dishes up structured fields and rows. Not so with Word (which you would sort of expect), and in fact there are a few thorny issues involved with consuming a word document.
To start with, some home truths about the Microsoft Word docx file:
- A Microsoft Word document docx format is actually a zip file. So to get to the contents we need to unzip it to a working location - this can be done via a One Drive or SharePoint action.
- The contents of the word document are stored in the OpenXML format in the extracted /word/document.xml file. In of itself not a problem - the problem lies with how changes and updates are stored. For example adding an s to a word will result in the original word and the s being wrapped in their own tags. By itself - not a problem but when we use Xpath or another form of xml querying/manipulation we need to account for it.
This article brilliantly outlines the approach of how to get the text from the document (https://www.tachytelic.net/2021/05/power-automate-extract-text-from-word-docx-file/).
What I'm going to attempt to demonstrate in this blog is one way in which we can apply structure and context to the text elements so that we can process them cleanly and efficiently.
Note: This article is written from the point of view of someone not very confident with XPath and XML manipulation. If one of you wizards out there has a way of performing the majority of the work in this post with a couple of straight forward XML scripts/actions that work in Power Automate then please share.
Talking about structure
So you've done all the unzipping and XPath work and now you have a lovely long list (one dimensional array) of text pieces that are in the order that they were encountered in the document.
Here's an example screenshot (from the new Power Automate Cloud flow designer):
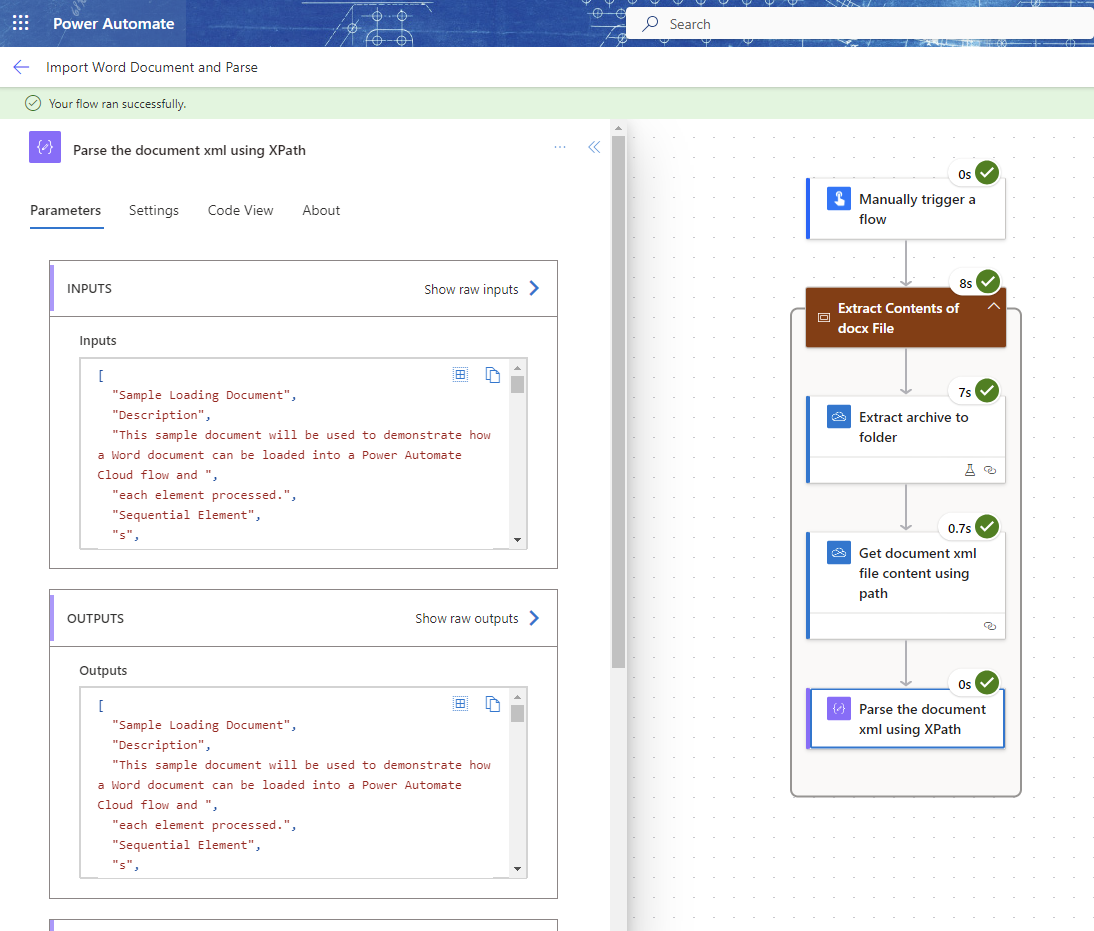
In case you're curious about the XPath logic that was used in the Compose Action here it is:
Lets talk structure - obviously the original word document has structure and organization to it (otherwise you'd be using a plain text file). We're going to be using an example document that has explicit examples of structures and layouts than can occur. These are expanded on in the following sections.
Sequential Elements

These elements are what you typically expect in a Word document - a label/heading or key followed by the desired value/information. The above examples get parsed into the following text elements:
"Sample Loading Document",
"Description",
"This sample document will be used to demonstrate how a Word document can be loaded into a Power Automate Cloud flow and ",
"each element processed.",
"Sequential Elements Examples",
"Text Example One",
"This is stuff we want",
" to get.",
"Text Example Two",
"This is another example of a text block.",
"Table Sequential Example",
" ",
" ",
" ",
" ",
"ID",
" ",
"",
"20212856",
"",
" ",
"Date",
" ",
"",
"09/02/2022",
"",
" ",
"Code",
" ",
"",
"BB",
"",
" ",
"Day Name",
" ",
"Friday",
We can interpret a processing pattern for something like this as: label1, value1, label2, value2, etc.
Tabular Elements
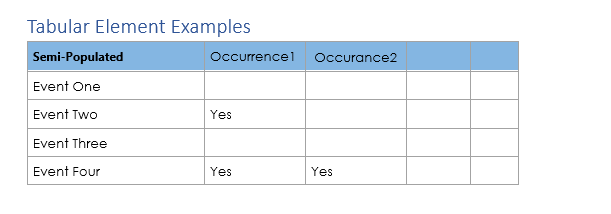
This is a variation of the following Matrix example where we can have anywhere from 1-4 (or higher for the generic case) columns, which may or may not be populated. Also the lack of population does not need to be recorded. The above example gets parsed into the following text elements:
"Tabular Elements Example",
"Semi-Populated",
"Occurrence1",
" ",
" ",
"Occurance2",
" ",
" ",
" ",
"Event One",
" ",
" ",
" ",
" ",
" ",
"Event Two",
" ",
"Yes",
" ",
" ",
" ",
" ",
"Event Three",
" ",
" ",
" ",
" ",
" ",
"Event Four",
" ",
"Yes",
" ",
"Yes",
" ",
" ",
" ",
An interpreted processing pattern for something like this would be: rowLabel1, columnValue1, rowLabel2, columnValue1, columnValue2, etc.
Matrix Elements

Unlike the Tabular elements example above, this time we have a fixed column set but the number rows are flexible, and we want to store if the value is populated or not. The above example parses into the following text elements:
"Matrix Element Example",
"Matrix of Options",
"Option One",
" ",
"Option Two",
" ",
"Option Three",
" ",
"Option Four",
" ",
"UserA",
" ",
" ",
"Yes",
"No",
" ",
" ",
" ",
"No",
"UserB",
" ",
" ",
"Yes",
"Yes",
" ",
"No",
" "
An interpreted processing pattern for this situation would be something like: rowLabel1_ColumnLabelA_Value, rowLabel1_ColumnLabelB_Value, ….rowLabel2_ColumnLabelA_Value, rowLabel2_ColumnLabelB_Value, ….
Identifying and processing structures
Small scale documents or elements desired
If you've got a small document, and/or you're only after a small subset of the text elements present you can pretty much get away with using a switch action/nested if statements to check what value you have and what to do next. This approach starts to get unwieldy the larger and more complex the document gets.
Processing Approach
If we can identify the types of elements we have, we can break them down into logical processing groups. I use the term processing groups because the way that you would process simple sequential elements is obviously different from how you would process tabular elements for example. Once we have each element identified we can then split the monolithic text element array into smaller more compact arrays that can be processed independently without having to worry about other structures that will break a processing path.
So, first thing to do is go through each of the text elements in the large monolithic one dimensional array and determine what type of processing group they are. We then store this alongside the actual value. So how to do the check? and how do we store in a way that helps us later on?
Checking for a group label
Since we are dealing with unknown values (which is the whole point of applying structure and context) we can only check for the things we expect - namely the group labels. For example, a group label in the Sequential Elements would be "Text Example Two", in the Tabular Elements - "Event Two", and in the Matrix Elements - "Matrix of Options". We store these labels of interest in array variables that can be used as references. The below screenshot shows one way of defining them all.
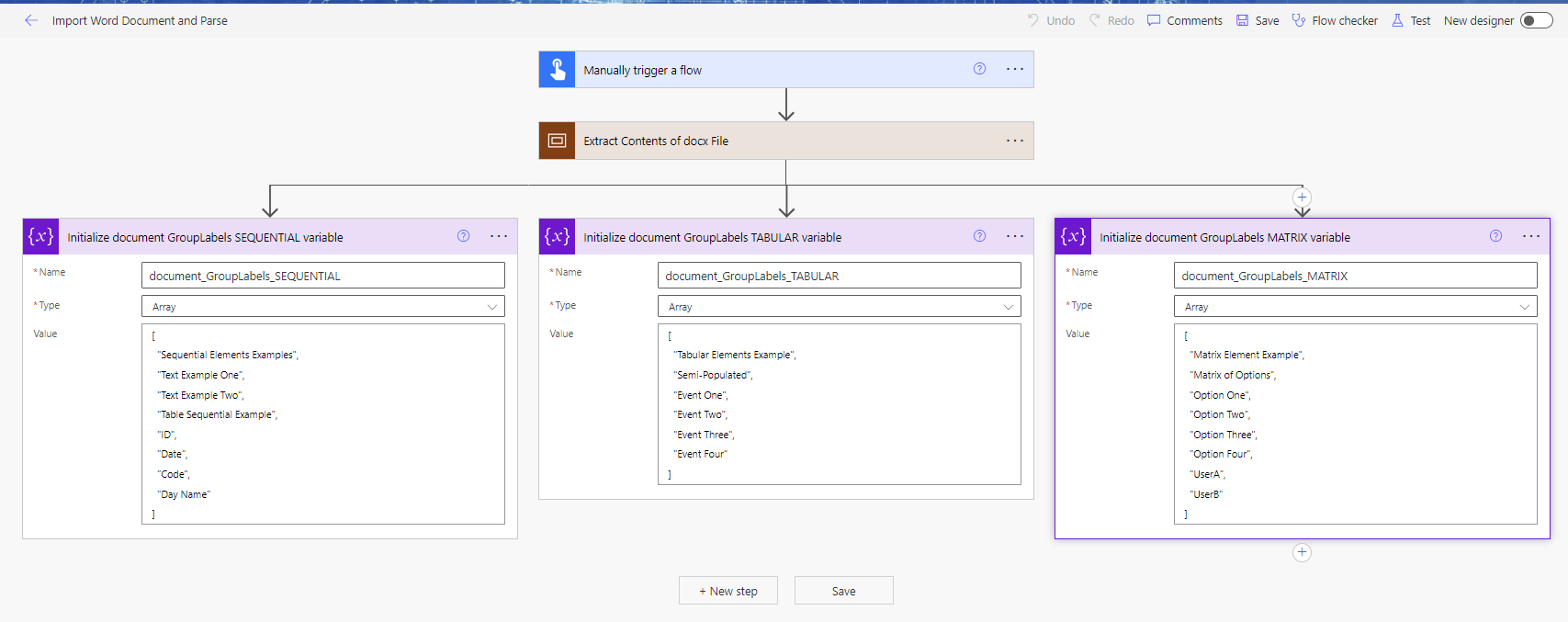
As we process each text element we need to compare it against each of the lookup array variables and see if we have a match. Rather than having to iterate through each one of these lookup arrays every time, we can leverage the intersection expression to see if we have a match. I'll show the implementation of this after discussing how we're going to store the processed data.
Storing processed data
As we go over each text element we want to determine what it's group label and relevant processing type are so that it can be used in later filtering and specific processing type work.
To store this information we create a new Array variable (semi_structured_input_data) that we append to for each text element in the following form:
{
"DocumentTextPiece":<<The current document text elements>>,
"GroupLabel":<<The group label that is matched from the appropriate lookup/reference array>>,
"ProcessingType": <<The processing type that is matched from the appropriate lookup/reference array>>
}
The semi_structured_input_data variable is used in downstream cloud flow work after the structural/context processing.
Setup, Iteration, and Evaluation
Now we are pretty much ready to begin - we do need to define supporting/working variables that will be used to hold the evaluated GroupLabel and ProcessingType during the looping. Also because I'm using the intersection expression I need to cast the working document text piece as an single element array, since the expression only works with arrays as inputs.
The following screenshot shows a possible layout of the setup ready to start iterating over the document text pieces. The source for the iterator is the output of the compose action that parsed the document xml using XPath.
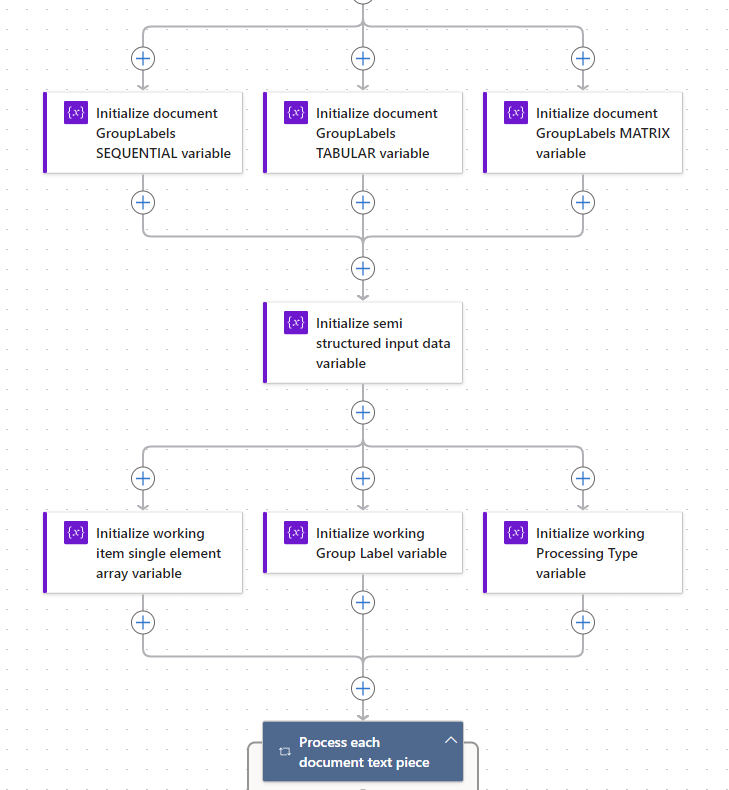
As we iterate over each text element we use nested IF logic to determine which GroupLabel array it may match with. Within each logic block we are performing the same type of check (except against a different array) and setting the appropriate value in the working variables.
Lets look at the SEQUENTIAL Logic block - we are checking if the text element (as a single element array) matches any element in the document_GroupLabels_SEQUENTIAL variable. This is done using the following formula:
length(intersection(variables('working_item_array'),variables('document_GroupLabels_SEQUENTIAL'))) > 0
Why use the length function? Well the intersection expression will return an array of the intersecting/matching values. If it is empty (i.e. length = 0) then there is no match. If we have a match then we set the working_GroupLabel variable to the current text element, and set the working_ProcessingType variable to a hardcoded "SEQUENTIAL" value.
If there is no match detected then we evaluate against the TABULAR array variable, and then the MATRIX array variable.
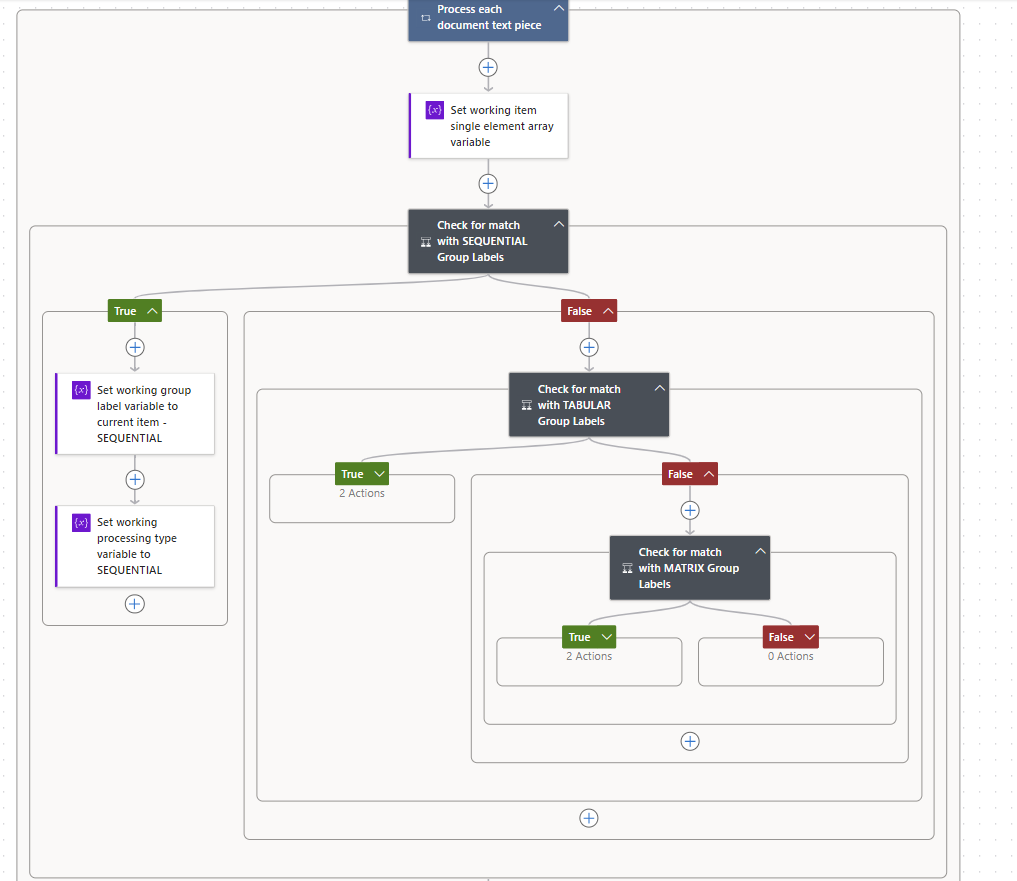
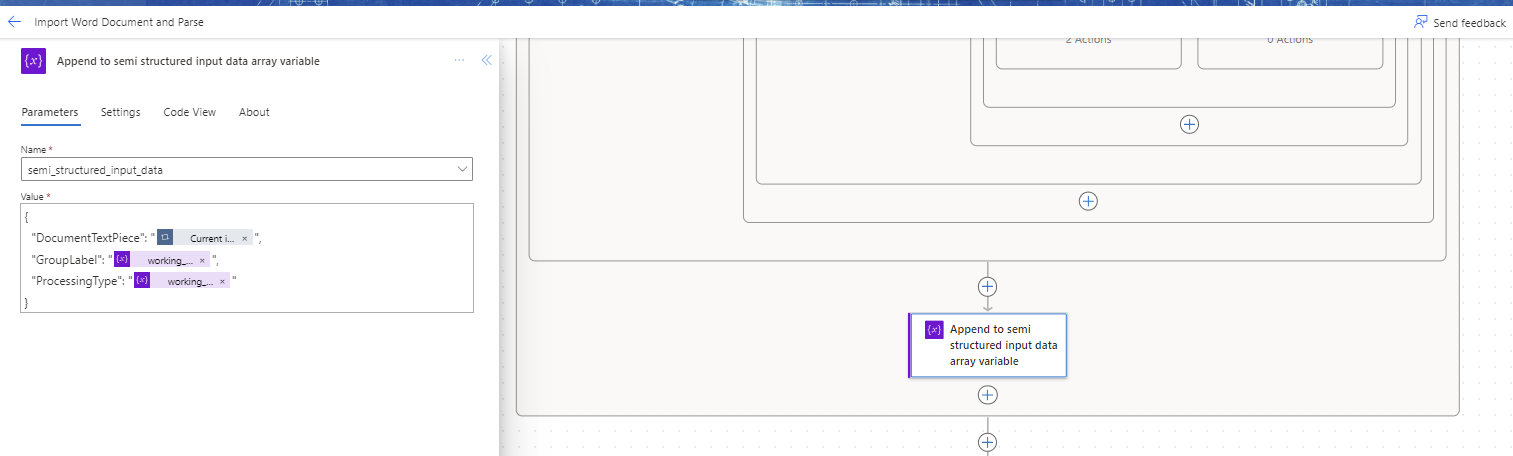
At the end of the evaluation logic we then append the combination of Text Element, Group Label and Processing Type values into our semi_structured_input_data array. Here's a partial example of the output:
{
"DocumentTextPiece": "Table Sequential Example",
"GroupLabel": "Table Sequential Example",
"ProcessingType": "SEQUENTIAL"
},
{
"DocumentTextPiece": " ",
"GroupLabel": "Table Sequential Example",
"ProcessingType": "SEQUENTIAL"
},
{
"DocumentTextPiece": " ",
"GroupLabel": "Table Sequential Example",
"ProcessingType": "SEQUENTIAL"
},
{
"DocumentTextPiece": "ID",
"GroupLabel": "ID",
"ProcessingType": "SEQUENTIAL"
},
{
"DocumentTextPiece": "",
"GroupLabel": "ID",
"ProcessingType": "SEQUENTIAL"
},
{
"DocumentTextPiece": "20212856",
"GroupLabel": "ID",
"ProcessingType": "SEQUENTIAL"
},
You may have spotted the loose thread here.
At the moment the approach for the GroupLabel/Processing is that the same value will be used for subsequent text elements until a new value is matched. This means that you if you have portions of the document that you wish to not process you can tag the top element and not tag the underlying elements, thus giving all of them the same group label - which you can then filter out. Conversely it means that you have many pieces tarred with the same brush.
Also the labels in the lookup array variables need to be unique in the document - if a label value occurs in the document, and then appears as an actual value somewhere else we'll have problems. For example if a field was the Day (name) that something happened - this label would clash with the Day value that can occur for a Day/Night field.
The current approach around this is to make the label name unique - but an alternative may be to allow a hierarchy of group labels (group/subgroup/subsubgroup) to uniquely locate a group label name. This would add more complexity to the structure processing.
So now we've applied some structure and context to our text elements - what's next? Well now it's quite simple to filter the main data set into individual processing type sets by using the Filter Array action. The below screen shot shows this setup for each of the different processing types:
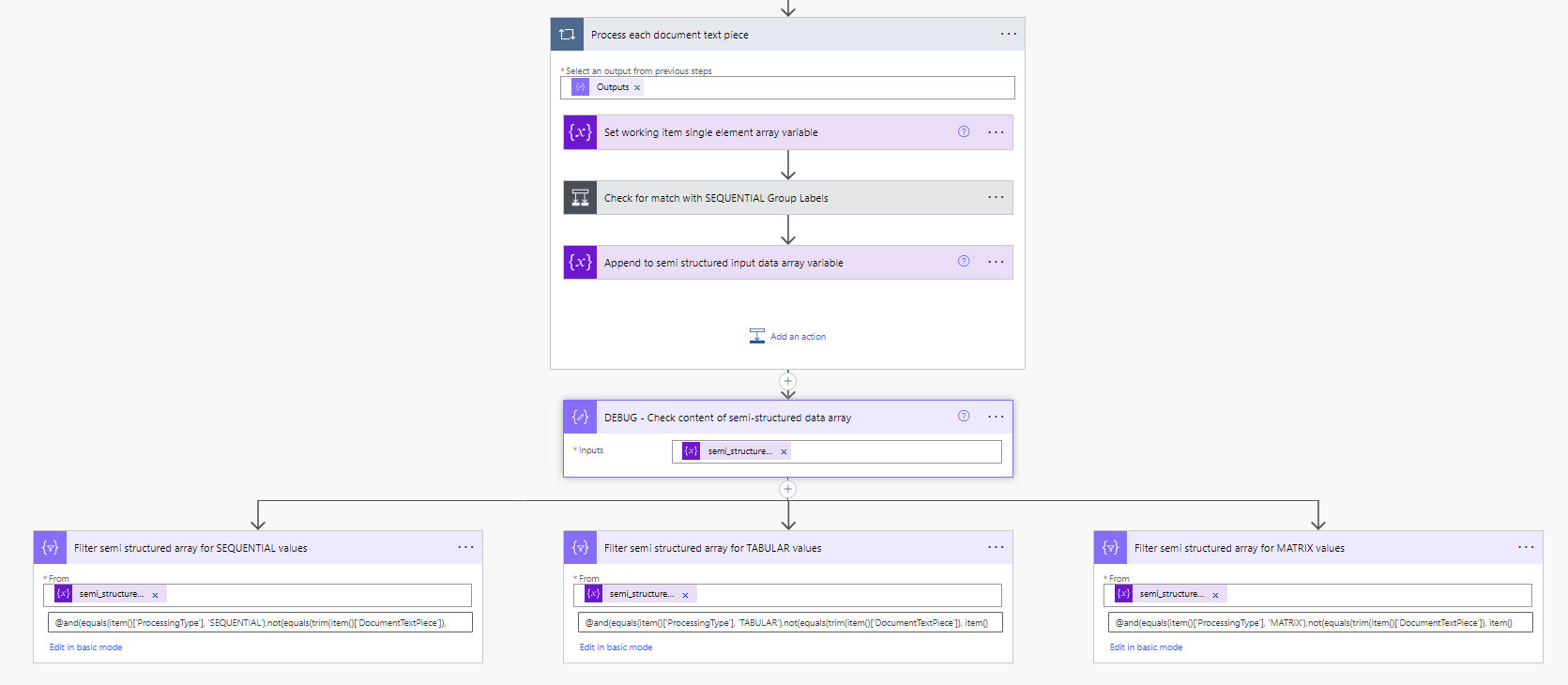
The expressions used in each filter action (advanced logic) are:
and(equals(item()['ProcessingType'], 'SEQUENTIAL'),not(equals(trim(item()['DocumentTextPiece']), item()['GroupLabel'])))
and(equals(item()['ProcessingType'], 'TABULAR'),not(equals(trim(item()['DocumentTextPiece']), item()['GroupLabel'])))
and(equals(item()['ProcessingType'], 'MATRIX'),not(equals(trim(item()['DocumentTextPiece']), item()['GroupLabel'])))
What each one is doing is obtaining the records with the desired processing type and excluding any records that have the DocumentTextPiece with the same value as the GroupLabel (since we now know what group label the value is associated with, we don't need to keep the label entries).
This is just an example and you can choose to apply whatever filtering you would like. In fact it can be easier (and clearer) to apply multiple sequences of filter actions, rather than one large complex collection.
After any filtering you're free to process the individual datasets as you require. Happy processing!
